1. Problem description
1.1 Background
LLMs are still frustratingly error-prone. They generate confident, fluent text that turns out to be factually wrong. The usual response is to catch false claims after the fact, with retrieval or external fact-checking. But what if the model's own internal states already carry a signal about what it knows and what it's making up?
That's the premise behind hallucination probes. Zou et al. (2023) showed that linear probes on an LLM's hidden states can reliably extract concepts like truthfulness and sentiment. Hedström et al. (2025) showed that once linear probes are trained, there exists a closed-form solution determining exactly how much to steer to reduce hallucinations. Obeso et al. (2025) applied this to detect hallucinated entities in long-form chatbot responses: they train a small classifier on the residual stream activations from a specific transformer layer, and the classifier predicts whether each token is part of a hallucinated span.
We reproduced their methodology for Apertus-8B-Instruct-2509 and Llama-3.1-8B-Instruct. As seen in our training notebooks, the probes that were trained on Llama-3.1-8B-Instruct residual stream activations worked well for hallucination detection. On Apertus-8B-Instruct-2509, probe performance was significantly degraded and training was unstable. We had started an investigation of active interpretability: where interpretability outcomes are not just post-hoc but serve as a guide for training signals. The investigation that followed led us to treat probes not just as classifiers for hallucination detection, but as diagnostic instruments of model discovery: their failure pattern told us what was wrong with the model before we knew what to look for.
1.2 The dataset
To train probes, we need labeled data: model-generated text where each span is tagged as factually supported or not. An example from our dataset is shown below. A user asks a question, the model generates a long response, and specific claims are checked against web sources. We show the user prompt and two sections of the model's response to illustrate how the annotation works: the first section contains a supported claim, while the second contains hallucinated specifics (fabricated mileage limits) that the annotation pipeline correctly flags.
**User**: Tell me about Formula 1's current testing regulations, particularly focusing on restrictions during the season, pre-season testing allowances, rookie driver testing requirements, tire testing protocols, and any special testing permissions for development work.
**Model**: As of my knowledge cutoff in 2024, Formula 1's testing regulations have undergone significant changes over the years [...]
### 1. Restrictions during the season
- **Seasonal Testing**: *Formula 1 teams are not allowed to conduct any official testing during the season*. [...]
- **Private Testing**: Teams are allowed to conduct private testing, but this is heavily restricted. [...]
### 2. Pre-season testing allowances
- **Pre-season Testing**: Formula 1 teams are allowed to conduct pre-season testing [...]
- **Testing Days**: The number of testing days is limited. For example, in 2024, each team was allowed a maximum of *100 kilometers of testing per day*, with a total of *1500 kilometers allowed across all pre-season testing sessions*.The annotated spans look like this:
[
{
"index": 356,
"label": "Supported",
"span": "Formula 1 teams are not allowed to conduct any official testing during the season",
"verification_note": "The FIA regulations restrict in-season testing to control costs and maintain fairness."
},
{
"index": 1260,
"label": "Not Supported",
"span": "100 kilometers of testing per day",
"verification_note": "No specific information found on a 100 kilometers per day limit; regulations normally specify total pre-season test days instead."
},
{
"index": 1311,
"label": "Not Supported",
"span": "1500 kilometers allowed across all pre-season testing sessions",
"verification_note": "No specific mileage limit per season found; FIA usually regulates the number of test days, not mileage."
}
]The dataset `LongFact++` from Obeso et al. (2025) was built in three steps: collect question prompts from `LongFact` (a Google-curated corpus), generate model answers, and annotate them using a larger LLM with a web search tool.
Web-search-based annotation matters here because it grounds the labels in real sources. An LLM judge without internet access might confirm a false claim if it looks plausible. Obeso et al. (2025) validated the pipeline in two ways. A human annotator independently labeled 50 random spans and agreed with the LLM's labels 84% of the time (though this only measures precision, not recall). On a controlled dataset with injected factual errors, the pipeline caught 80.6% of them (729/904), with a 15.8% false positive rate on correct content.
Obeso et al. (2025) extended LongFact to ~20k questions across diverse topics, generated answers using several models (Llama-8B-Instruct, Llama-70B-Instruct, Mistral-Small-24B-Instruct-2501, and others), and annotated them using Anthropic Claude Sonnet 4 with web search.
To build probes for Apertus-8B-Instruct-2509, we ran both the generation and annotation pipelines ourselves, producing our own version of LongFact++, available on HuggingFace. We generated data for both Apertus-8B-Instruct-2509 and Llama-3.1-8B-Instruct. A perfect reproduction wasn't possible because the original pipeline wasn't fully documented, but the resulting datasets are close to the originals in both volume and distribution, as shown later. The full reproduction details are in the project report at our Github repository.
1.3 Probe training
The choice of which transformer layer to probe matters more than we initially realized. Each probe is trained on the residual stream activations from a single layer. Both Apertus-8B-Instruct-2509 and Llama-3.1-8B-Instruct have 32 layers total. Following Obeso et al. (2025), we initially trained probes on layer 30 activations only. Neither the original authors nor we ran a systematic layer-by-layer comparison at first. This mattered more than we expected. We also experimented with concat and attention probes (Kantamneni et al., 2025), where we found similar instability patterns in the deeper layers for Apertus-8B-Instruct-2509.
The probes use a standard cross-entropy loss for binary classification. To improve performance, Obeso et al. (2025) also used LoRA with weight updates (Low-Rank Adaptation, Hu et al., 2021): small trainable adapters that project residual stream activations into a lower-dimensional space before the classifier head. The idea is that LoRA can learn to extract task-relevant directions in the activation space that a linear probe operating on the full hidden dimension might miss. For the full training setup, we refer to the original paper.
2. The problem
Initially, the Apertus-8B-Instruct-2509 probes performed much worse than the Llama-3.1-8B-Instruct probes. This was surprising on its own, but it gets even more surprising: we evaluated both probes on Apertus-8B-Instruct-2509-generated text. The probe trained on Llama-3.1-8B-Instruct residual stream activations (a completely different model) still outperformed the probe trained on Apertus-8B-Instruct-2509's own activations, despite both probes being evaluated on the same Apertus-8B-Instruct-2509 completions.
To understand where things break down, we trained separate probes on residual stream activations from each of the 32 layers and measured AUC on a held-out test set. Fig. 1 shows the results.
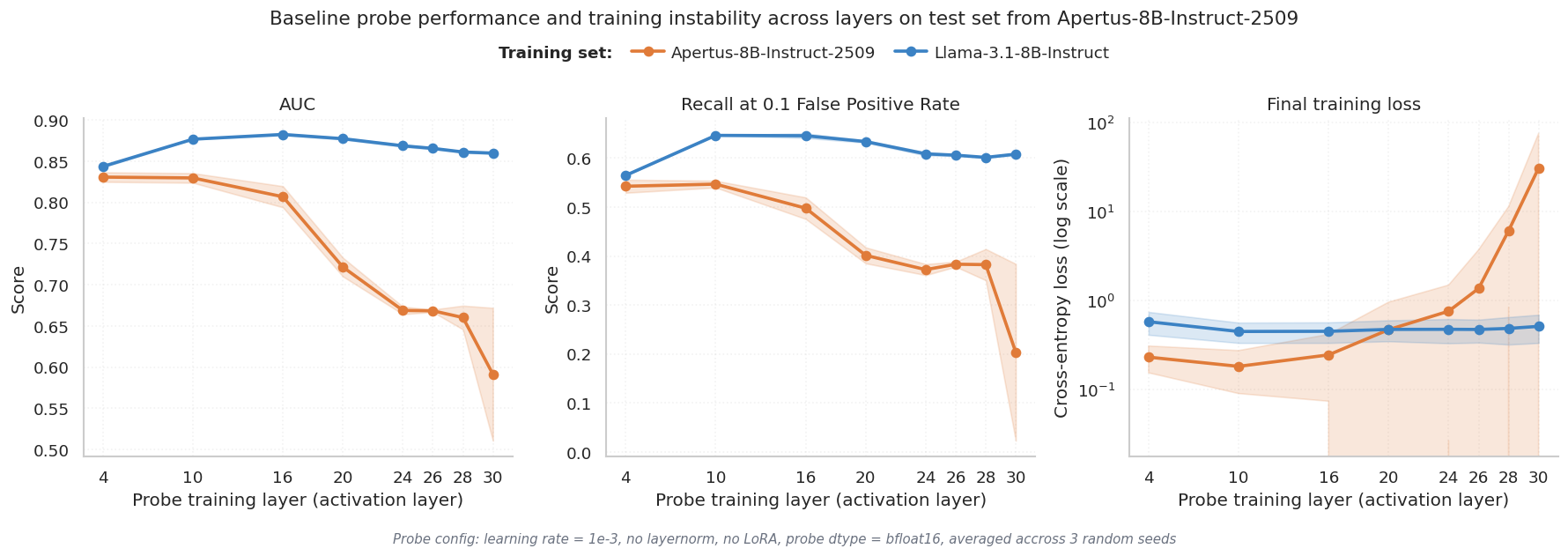
Fig. 1 shows AUC (y-axis) for probes trained on each layer (x-axis), with separate lines for Apertus-8B-Instruct-2509 (orange) and Llama-3.1-8B-Instruct (blue). The Llama-3.1-8B-Instruct probe performance is relatively stable across layers, hovering around 0.85 AUC from layer 10 onward. The Apertus-8B-Instruct-2509 probe tracks Llama-3.1-8B-Instruct's performance until around layer 16, then drops sharply, falling below 0.70 by the final layers. This is unexpected: deeper layers in transformers typically encode more abstract, higher-level representations, so you'd expect probe performance to improve or at least stay flat. Instead, something is actively degrading the signal in Apertus-8B-Instruct-2509's later layers. The training loss for those layers also becomes erratic, which points to an optimization problem rather than a missing signal.
3. Diagnosing the instability
In the following, we diagnose the instability in probe performance shown in the previous section. We systematically rule out data issues and then look directly at the model's internal representations.
3.1 Loss scale
The first thing we checked was whether the training loss itself looked different between the two models.
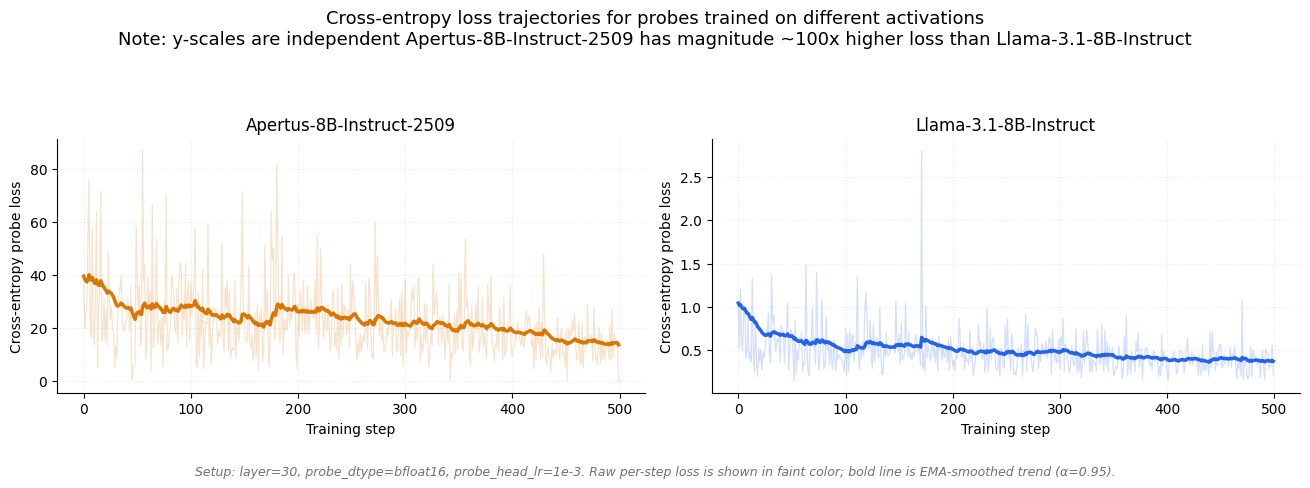
Fig. 2 shows training loss over optimization steps for both models. Two things stand out. First, the Apertus-8B-Instruct-2509 loss (orange) is roughly 100x larger than Llama-3.1-8B-Instruct's (blue) in absolute terms. Second, it's much spikier, with large jumps between consecutive steps. Despite this, the Apertus-8B-Instruct-2509 loss does trend downward, so the training does converge in a loose sense, but the probe still performs badly. The 100x scale difference was our first concrete clue that something is off about the raw magnitude of Apertus-8B-Instruct-2509 activations of the first model release.
3.2 Dataset validity
Before blaming the model, we checked whether our data pipeline introduced the problem. We compared both datasets along several dimensions: annotation quality, hallucination rates, completion lengths, span lengths, and train/test overlap.
| Source | Model | Split | Rows | Spans/Row | Invalid Rate | Halluc. Rate | Completion Length (mean) | Completion Length (median) | Span Length (mean) | Span Length (90th percentile) |
|---|---|---|---|---|---|---|---|---|---|---|
| ours | Apertus-8B-Instruct-2509 |
train | 17,986 | 9.59 | 0.025 | 0.236 | 3,014 | 2,778 | 25.66 | 52 |
| ours | Apertus-8B-Instruct-2509 |
test | 1,993 | 9.61 | 0.025 | 0.240 | 2,987 | 2,733 | 26.08 | 54 |
| ours | Llama-3.1-8B-Instruct |
train | 17,959 | 11.99 | 0.028 | 0.264 | 3,918 | 3,728 | 25.31 | 50 |
| ours | Llama-3.1-8B-Instruct |
test | 1,996 | 11.78 | 0.029 | 0.269 | 3,915 | 3,708 | 25.71 | 50 |
| paper | Llama-3.3-70B-Instruct |
train | 7,959 | 15.59 | 0.021 | 0.261 | 3,890 | 3,735 | 20.72 | 41 |
| paper | Llama-3.1-8B-Instruct |
train | 7,919 | 14.44 | 0.023 | 0.367 | 3,687 | 3,474 | 22.43 | 45 |
| paper | Mistral-Small-24B-Instruct-2501 |
train | 1,534 | 14.20 | 0.034 | 0.170 | 3,567 | 3,560 | 19.87 | 39 |
| paper | Qwen2.5-7B-Instruct |
train | 1,524 | 12.64 | 0.045 | 0.350 | 3,782 | 3,757 | 21.60 | 43 |
| paper | Gemma-2-9B-it |
train | 1,495 | 10.94 | 0.048 | 0.186 | 2,837 | 2,781 | 19.47 | 37 |
The hallucination rates are well-matched (~24% for Apertus-8B-Instruct-2509, ~26% for Llama-3.1-8B-Instruct), there are no train/test leaks, and manual spot-checks of individual datapoints didn't reveal annotation artifacts. Apertus completions are slightly shorter on average, but nothing here explains the performance gap. The data is not the issue.
3.3 Activation clustering
With the dataset ruled out, we looked at the activations directly. If hallucination is linearly separable in the activation space, you'd expect some separation between hallucinated and supported tokens when you project them down to 2D.
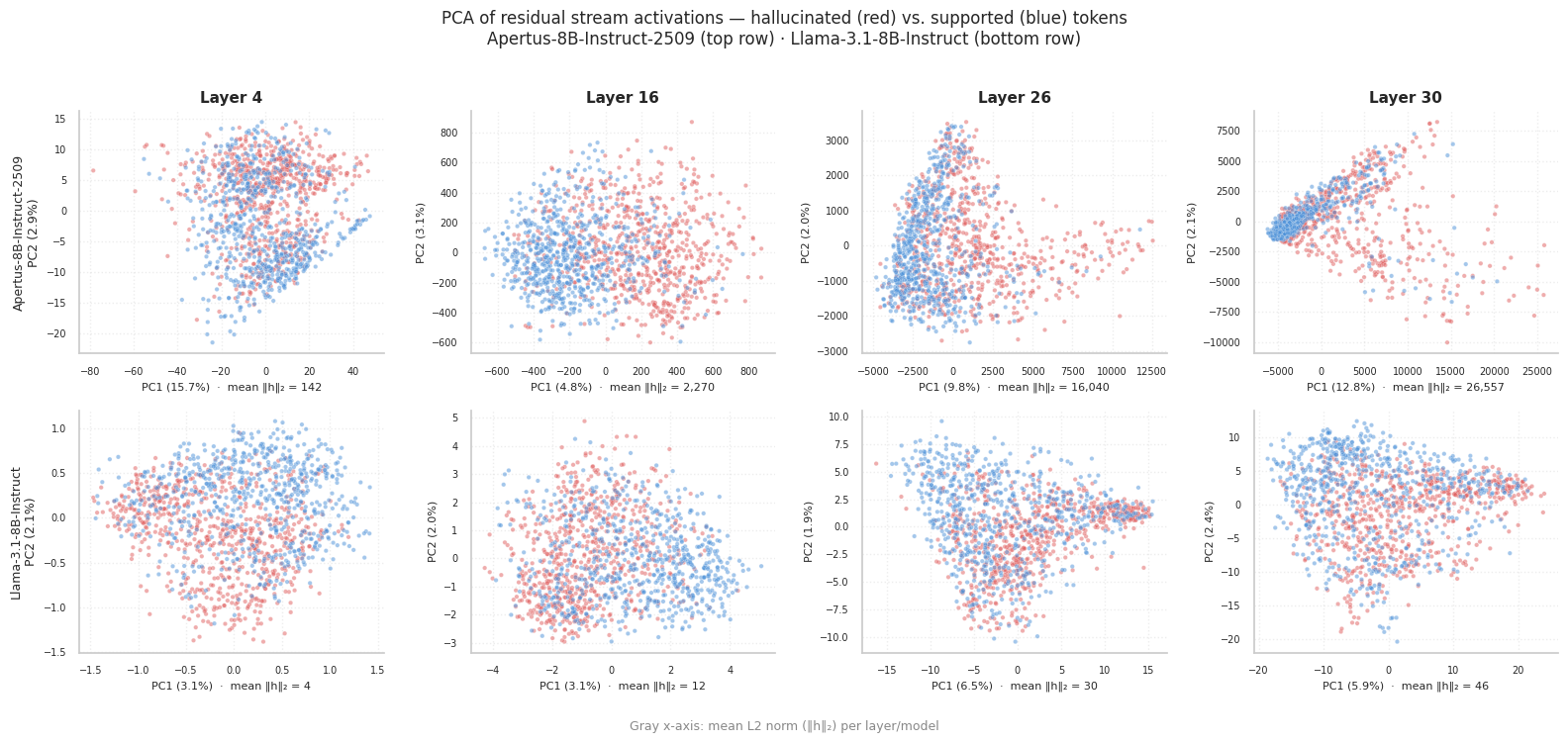
Both models show some clusters in PCA space (Fig. 3), which is encouraging: a linearly decodable hallucination pattern is present in both models. But the scale of the two plots is very different. Llama-3.1-8B-Instruct activations form relatively tight clusters. Apertus-8B-Instruct-2509 activations are far more spread out (check the axis ranges). The hallucination signal exists in Apertus-8B-Instruct-2509, but it's buried in much more variance.
3.4 Activation norms
To put numbers on the spread we saw in PCA, we measured the mean L2 norm of residual stream activations at each layer for both models.
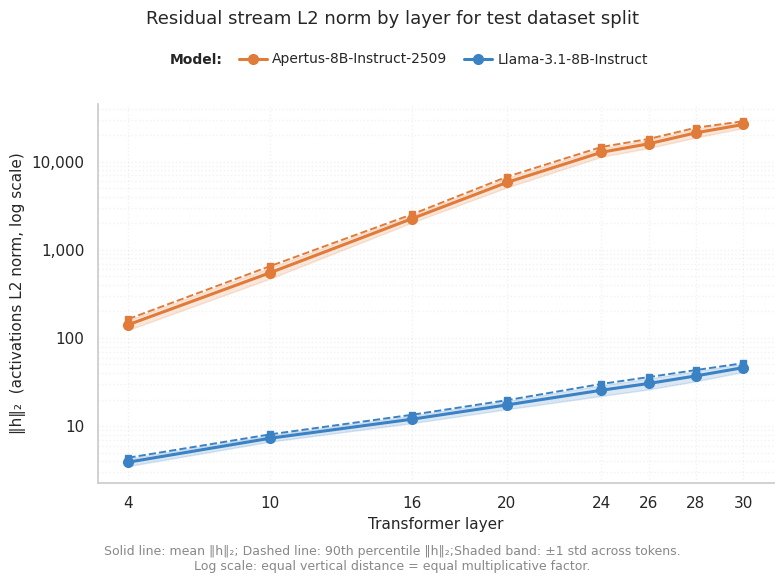
Fig. 4 shows mean activation L2 norm (y-axis) across layers (x-axis). Some growth is normal in transformers: the residual stream accumulates contributions from each layer, so norms tend to increase (for background, we refer to this post). But the scale here is the problem. Llama-3.1-8B-Instruct norms grow modestly and plateau. Apertus-8B-Instruct-2509 norms grow exponentially and are over 100x larger than Llama-3.1-8B-Instruct's in the deeper layers. This 100x ratio matches the 100x loss difference we observed earlier. Activations this large cause trouble for bf16 arithmetic (which has limited precision for large numbers), scatter gradients during optimization, and make it hard for the probe to find a stable decision boundary.
4. Our hypothesis
The evidence all points in one direction: Apertus-8B-Instruct-2509 has exploding activations in its deeper layers. The magnitudes grow far beyond what standard probe training can train on, causing numerical instability in bf16, noisy gradients, and degraded probe performance.
Julian Minder independently flagged this issue in our internal interpretability talks and pointed us toward several potential fixes.
The long-term fix is to address the root cause in the model itself and release an Apertus-8B-Instruct-2509 version without this exponential growth in activations. But we wanted to test the hypothesis first: if the instability really comes from activation magnitudes, then interventions that normalize or dampen those magnitudes should improve probe stability and performance. If the problem was something else, like missing hallucination signal in Apertus-8B-Instruct-2509's residual stream, these fixes would do nothing.
5. Proposed solutions
We tried four interventions, each targeting the problem from a different angle:
fp32instead ofbf16:bf16has limited range for large numbers, so rounding errors can cascade during training.fp32should help.- Smaller learning rate: large activations produce large gradients. With a big learning rate on top of that, parameter updates overshoot and the optimizer never settles. We reduced it from
1e-3to3e-4. LayerNormbefore the probe: normalize activations to zero mean and unit variance before the probe sees them. This removes the magnitude problem directly. It also improves numerical accuracy, since floating point is much more precise near zero than at extreme scales (Ba et al., 2016).LoRAadapters: as in the original paper.LoRAlearns a low-rank projection of the activations, which helps with task alignment, but may also act as compression that filters out some of the high-variance noise.
6. Results
The four fixes helped to different degrees. We go through each one below, then show the combined effect.
6.1 Stronger precision
Switching from bf16 to fp32 doesn't change the geometry of the activations. The probe is still trying to find a decision boundary in a space with very high variance. But it gives the floating point representation more room to encode those large numbers without rounding errors.
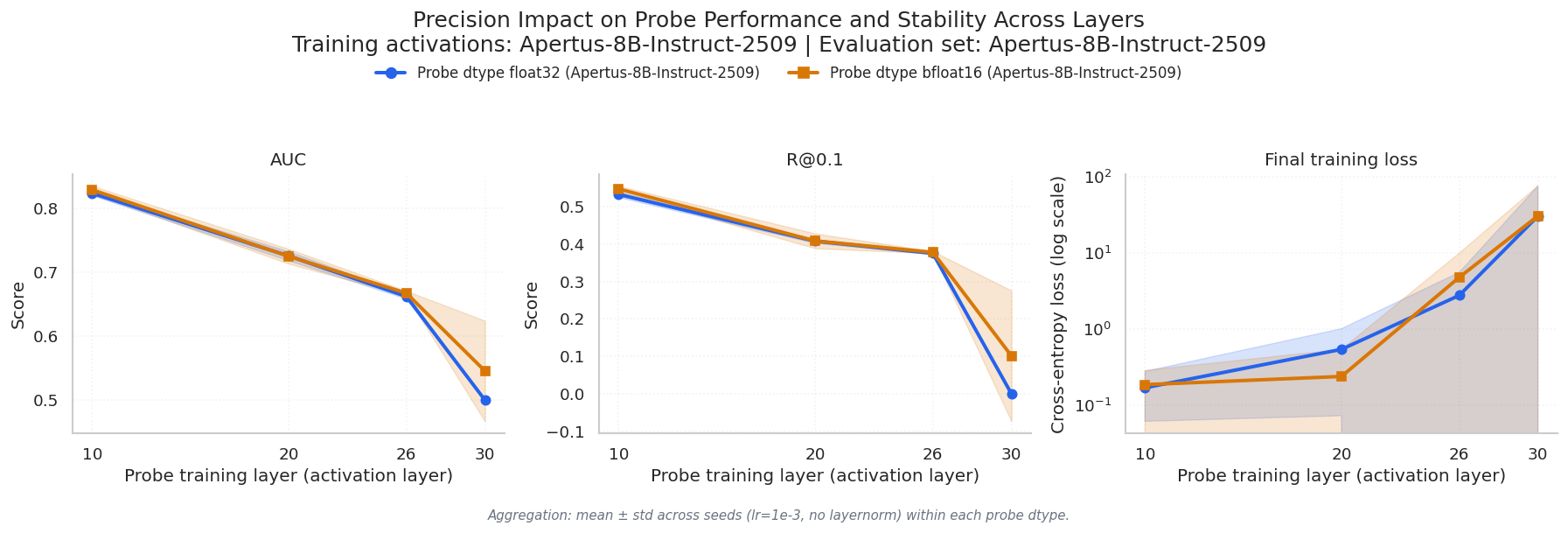
As shown in Fig. 5, the fp32 runs are noticeably less noisy: the loss curves are very consistent across seeds. But this stability gain didn't translate to better final performance. The probe AUC barely changed. Better precision helps the optimizer run more smoothly, but the underlying problem (huge activation magnitudes) is still there.
6.2 Smaller learning rate
When activations are large, gradients are large too. A learning rate that works fine for normal-scale activations can cause the optimizer to overshoot and scatter around the minimum instead of converging to it.
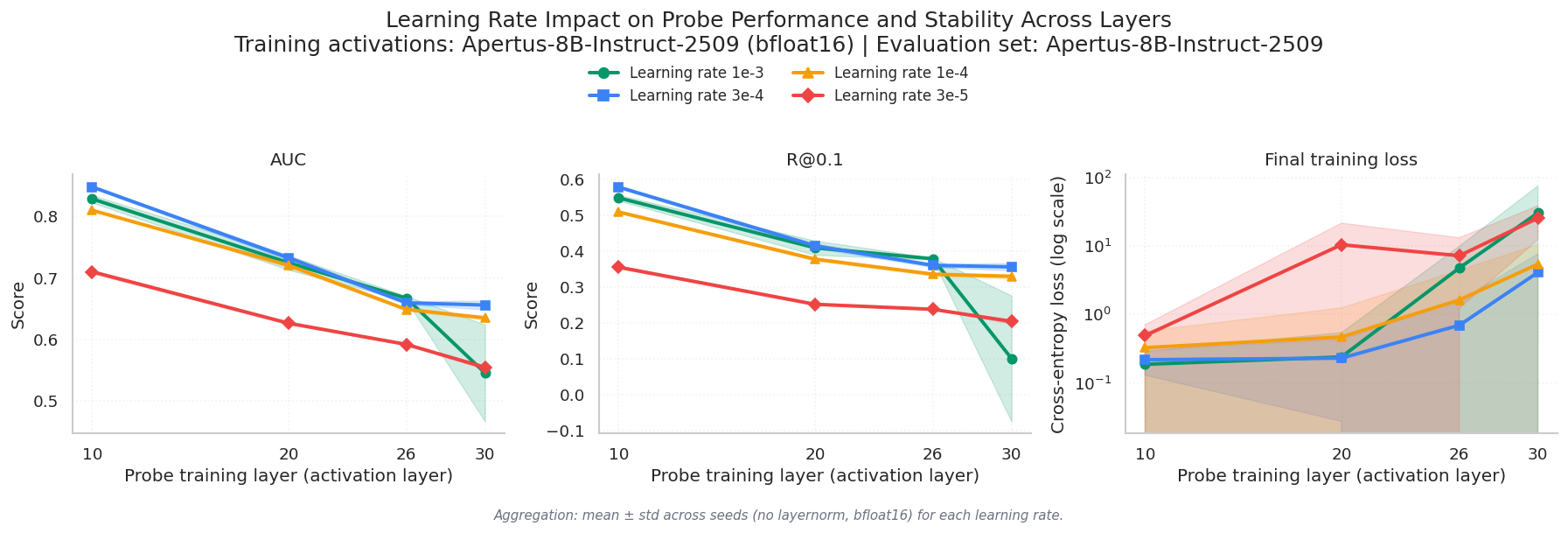
As shown in Fig. 6, reducing the learning rate from 1e-3 to 3e-4 stabilized the runs and slightly improved performance. The loss curves became less erratic and more consistent across seeds. The improvement on its own is modest, but it compounds well with the other fixes.
6.3 `LayerNorm`
If the core problem is activation magnitude, the most direct fix is to normalize the activations before the probe sees them.
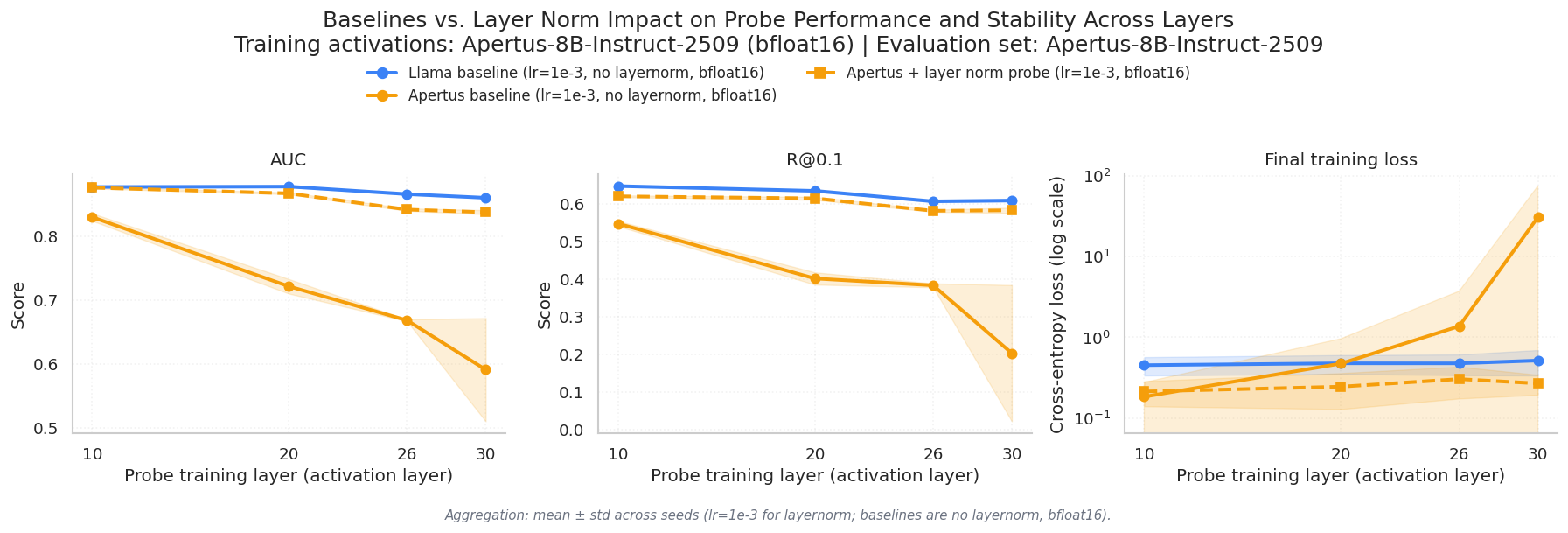
LayerNorm made the biggest single difference (Fig. 7). With normalization, the Apertus-8B-Instruct-2509 probe performs almost as well as the Llama-3.1-8B-Instruct probe. This is strong evidence for the exploding activations hypothesis that we postulated in previous sections. If the problem were deeper, like Apertus-8B-Instruct-2509 simply not encoding hallucination signal in its residual stream, normalization wouldn't help. The fact that it nearly closes the gap with Llama-3.1-8B-Instruct tells us the signal was always there. It was just buried in magnitudes that the probe couldn't train on.
6.4 `LoRA`
LoRA adapters learn a low-rank projection that aligns the activations more closely with the classification task. In the Apertus-8B-Instruct-2509 case, there's a second benefit: compressing the high-dimensional, high-variance activations into a more compact representation where the probe can find a cleaner decision boundary.
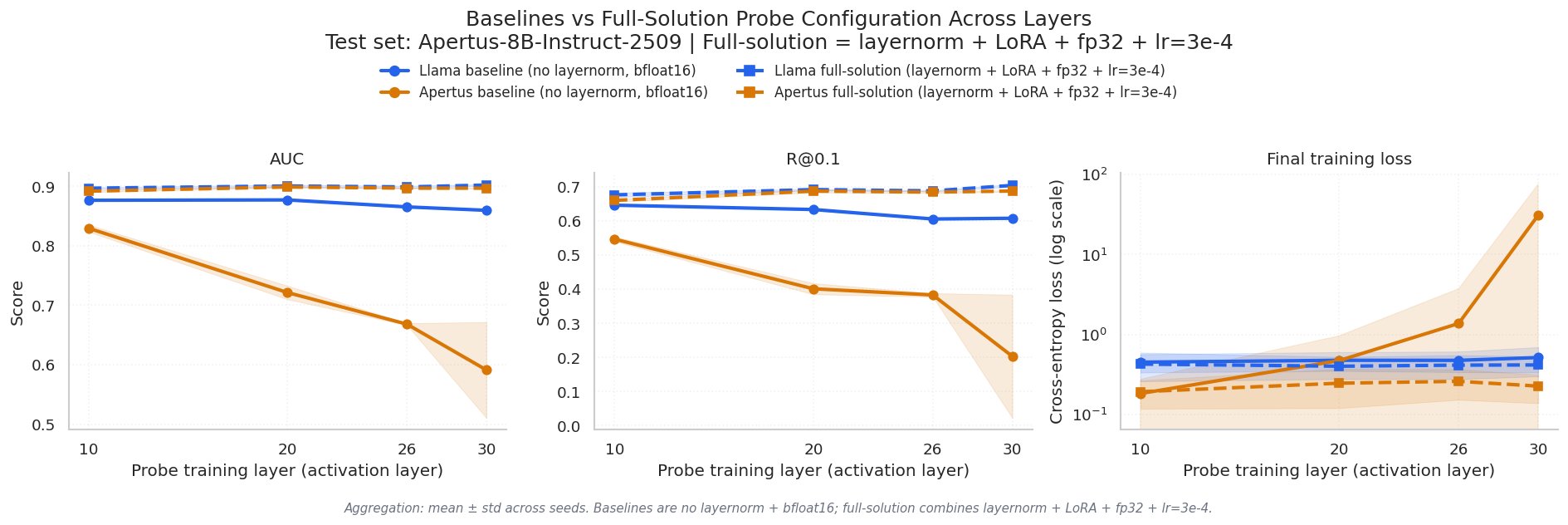
As shown in Fig. 8, LoRA improved performance both with and without the other fixes, consistent with what Obeso et al. (2025) reported for other models. The improvement stacks with LayerNorm and the other interventions.
6.5 Combined results
The full solution (all four fixes combined) is summarized below:
| Probe model (train) | Evaluation set | Metric | Baseline mean | Full-solution mean | Absolute improvement |
|---|---|---|---|---|---|
Apertus-8B-Instruct-2509 |
Apertus-8B-Instruct-2509 |
AUC | 0.7025 | 0.8961 | +0.1935 |
Apertus-8B-Instruct-2509 |
Apertus-8B-Instruct-2509 |
Recall at 0.1 FPR | 0.3837 | 0.6802 | +0.2966 |
The AUC jump of ~0.19 puts the Apertus-8B-Instruct-2509 probe in the same range as what Obeso et al. (2025) report for Llama-class models, meaning the probe can now reliably distinguish hallucinated spans from supported ones at a level comparable to probes trained on models without activation instability. The recall improvement at 0.1 FPR (+0.30) matters even more in practice: real-time hallucination detection systems operate under tight false positive budgets, and more than doubling recall at that threshold makes the probe usable rather than a curiosity.
6.6 Stability
The stability gains on the training loss are just as important as the performance gains:
| Stability indicator | Baseline | Full-solution | Change |
|---|---|---|---|
| Mean final training loss | 8.236 | 0.232 | 97.2% lower |
| Seed-level loss std (avg over layers) | 11.887 | 0.099 | 99.2% lower |
For reference, the baseline Llama-3.1-8B-Instruct probe achieves a mean final loss of 0.480. Our full-solution Apertus-8B-Instruct-2509 probe reaches 0.232, which is actually lower than the Llama-3.1-8B-Instruct baseline, despite starting from activations that were causing 100x larger losses. The near-elimination of seed-level variance (99.2% reduction) means probe training is now reliable and reproducible, which is a basic requirement for any real deployment.
7. Why is this important
The finding itself, that Apertus-8B-Instruct-2509 has exploding activations, is useful but not surprising on its own. Large activation norms in deep transformers are a known failure mode. What we think is more interesting is how we found it and what that says about interpretability techniques as a tool to discover model artifacts and subsequent clues on how to improve.
In the beginning of this project, we didn't set out to diagnose activation instability. We wanted to build hallucination probes. The probes failed, and their failure pattern told us something was wrong with the model's internals. The layer-by-layer AUC drop was the first clue. The 100x loss difference, the PCA spread, and the norm measurements followed. Each step narrowed the hypothesis until we had a clear diagnosis and a set of targeted fixes.
That's the active interpretability angle. Instead of treating probes as post-hoc black-box classifiers (they either work or they don't), you treat them as instruments of model discovery. When a probe fails, the way it fails is informative. A performance drop in deeper layers means something different than a uniform failure across all layers. A 100x loss difference points you toward numerical issues, not data problems.
We think this approach carries over to other settings. We've seen similar activation behavior in other models, and the same diagnostic pattern applies: train a probe, observe how it fails, use the failure pattern to form a hypothesis, test the hypothesis with targeted interventions. The fixes here were simple (LayerNorm, lower learning rate, fp32, LoRA). The hard part was knowing which fixes to try, and the probes told us that.
Our next steps include adapting these probes for production use. We also expect the activation growth to be addressed in upcoming Apertus-8B-Instruct-2509 releases. We hypothesize that the choice of activation function during pre-training may be a root cause of the exploding activation values, following the analysis in Huang et al. (2025), who showed that certain activation functions can lead to unbounded norm growth in deep residual networks. Regardless of whether the root cause is fixed at the model level, this investigation demonstrated that interpretability tools can provide value well beyond their original project scope: what started as a hallucination detection effort ended up surfacing an architectural issue and informing the next training run.
Comments
Sign in to join the conversation.
Sign in to commentNo comments yet.